
.key-points {
color: #ffffff;
max-width: 900px;
padding-left: 40px;
margin-bottom: 55px;
margin-top: 55px;
padding-top: 20px;
padding-bottom: 20px;
background-color: #191F23;
font-family: "gotham";
border-radius: 0px 0px 0px 50px;
}
.key-points-link {
color: #7ecdc8 !important;
font-size: 18px !important;
}
.key-points-items {
margin-top: 20px;
color: #7ecdc8;
font-weight: 600;
margin-left: 2px;
margin-right: 3px;
}
.key-points-header {
font-family: avant-garde, sans-serif;
font-weight: bold;
font-size: 25px;
line-height: 1.2;
}
.key-points-items .sublevel {
margin-left: 20px;
line-height: 1.2;
}
- Introduction & scope of this article
- Data quality has been an issue for too long
- So, why are organizations not fixing Data Quality issues?
- The case for a comprehensive, yet lightweight data quality framework
- 6 Steps to approach implementation of a modular Data Quality framework
- How to nail technical details and boost your Data Quality Management?
Introduction & scope of this article
In recent years, as industries have shifted towards data-driven decision-making, the effects have become more impactful: If data is not good enough to train machine learning models, if management dashboards are not accurate enough, fallacies increase, and the quality of business decisions suffers. Quality issues and errors in data are plenty, they are expensive to fix, and no one can really assess the damage they cause.
This article covers process design and how to implement frameworks.
In case you like to learn more about the technical aspect of Data Quality Frameworks, practial implementation details, and how to boost Data Quality Management with machine learning capabilities, you can have a look at Vera’s article on our partner brand website Positive Thinking Company: how Machine Learning enhances Data Quality Management.
Data quality has been an issue for too long
In recent years, as industries have shifted towards data-driven decision-making, the effects on data quality have become more impactful. If data is not good enough to train machine learning models, if management dashboards are not accurate enough, fallacies increase, and the quality of business decisions suffers.
Quality issues and errors in data are plenty, they are expensive to fix, and no one can really assess the damage they cause. Data quality issues themselves come in loads of forms – to name a few examples:
- Similar information is stored in different data formats across various systems.
- Customers have given wrong information due to misleading forms.
- Employees are cleverly omitting necessary information because it would not affect them personally.
- Automatic data consolidation processes are not covering few special data constellations.
The root causes for all these errors vary greatly and almost always require an individual analysis that can be quite time-consuming. But this is no news to anyone, as the problems have been around long enough.
So, why are organizations not fixing Data Quality issues?
Here are 5 kinds of struggles regarding data quality that we have observed in the past:
- There are rarely any direct monetary benefits for the organization. Lack of data quality prevents the gain of information from data but fixing quality findings does not directly lead to increased sales or margins. It is more likely that increasing data quality will enable an organization to gain insights that will lead them to proper action, but it’s nearly impossible to make the benefit completely transparent.
- Cultural rebuff of grassroots initiatives, especially by middle management, tends to slow down whatever momentum such an initiative has had, in no time. This is not a problem exclusive to data quality measures, but it can be difficult to allocate budget for appropriate measures if the overall initiative is not adequately backed.
- A lack of internal data governance roles and assigned responsibility for data naturally limits any data quality activities. Identifying errors and aggregating quality KPIs (Key performance indicators) is only one part of the process. The organizationally challenging part only starts there: Now that the errors are known, how should we handle them? The mitigation, fixing, or acceptance of data errors are usually case-by-case decisions.
- There are plenty of data quality tools on the market, but when introduced in a corporate environment, they are rarely applied to their full potential, or have significant functional overhead that presents a major obstacle for user acceptance.
- Data quality rulesets are likely extended over time and become very difficult to manage. It is also not feasible to cover all quality requirements with explicit rules and monitor results of these checks. That leads to increasing resource demands for operating the DQ (Data Quality) process, which can easily overwhelm organizations and lead to inefficiencies.
To summarize:
Tackling data quality professionally is difficult, costly, unattractive, and comes with a long string of consequences for the organization. That is why we propose a modular solution that can be started small and extended over time, scaled exactly to immediate needs.
The case for a comprehensive, yet lightweight data quality framework
These pain points have led us to develop a modular framework that can tackle the various challenges data quality poses to enterprises.
As a basis for all technical implementation, designing processes and a target operating model for data quality must be the first steps. That includes determining where and when to check data quality, who sets data quality requirements, how to present results, how to prioritize findings, and how operations should be funded.
In terms of operational processes, organizations should aim to continuously improve their quality as well as the accuracy and completeness of their data quality checks. We propose the following high-level, repetitive process as a means of orientation for developing a detailed version specifically tailored to the respective organization:
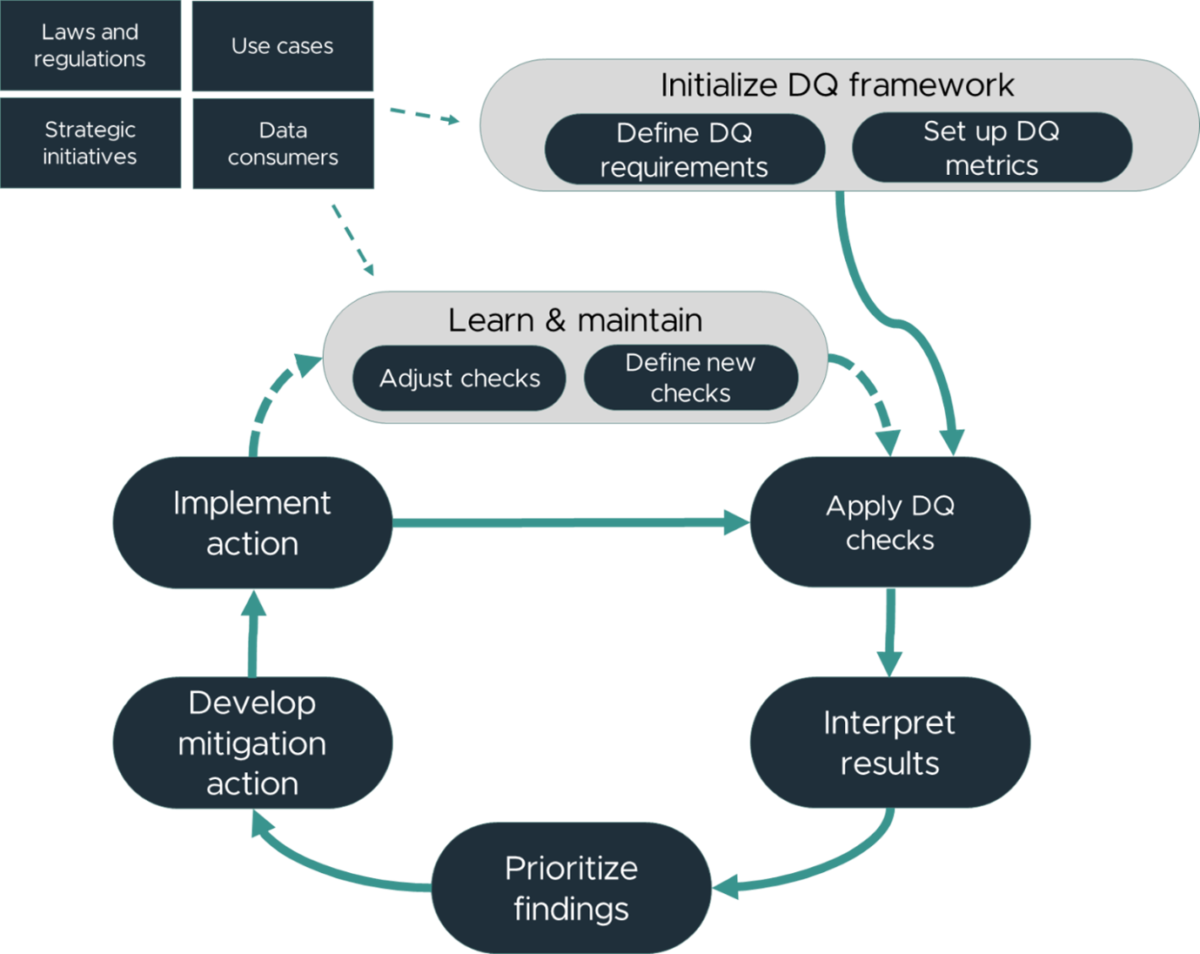
6 Steps to approach implementation of a modular Data Quality framework
Influential factors for the scope and extent of a DQ framework
There are several factors that influence the setup of a data quality management system. Data consumers, users of data inside or outside the organization, may have specific requirements and need for the quality of their data having different focus needs. (Note: They likely just want it to be “good” without being able to further detail what “good” means specifically.) Depending on the use case, requirements might differ a lot. For some, availability is most important, others can not deal with missing values or need certain data to be extremely accurate.
Strategic initiatives might want an overall framework that makes data quality comparable over different business units, bringing in additional requirements. Also, strong regulations like in the financial industry or privacy laws like the GDPR influence the requirements that one has towards the quality of the data.
These factors shape the perspective on data quality and are determining the design of necessary processes.
First things first: Laying a solid foundation
Before setting up an operational process that continuously improves the quality of corporate data, requirements need to be collected and generic data quality metrics must be defined that suit the company’s needs. Metrics are quite individual; they are important to aggregate checks and communicate results. Metrics can be percentages, traffic lights or numeric/lettered levels with certain adjustable threshold values, or arithmetic figures like averages, means and standard deviation. The specific implementation depends on the types of checks to be aggregated and the company’s management culture. Defining this is a critical step since all ensuing efforts will be based on this outcome.
Modular structure enables flexibility
As a next step, requirements need to be translated into modular quality checks that each check for exactly one criterion (atomicity). They must also not overlap in their checks and should be generically applicable to your data, but on the other hand configured for specific needs, like templates. The checks might be easy-to-answer or more complicated statistically or machine learning supported.
Depending on the type, results can have:
- binary format,
- percentage-based outcomes
- categorized scores.
Additionally, data will be augmented by concrete values like currencies, a list of statistically outlying records, or otherwise noticeable data like unusual data drifts.
Results mean nothing without context
The check results need to be interpreted in the next step, translating the outcome to a generic measurement for specific quality requirements – e.g. a traffic light system for specific external reporting. This translation should be accounted for by a dedicated role, e.g. a Data Quality Officer, who is familiar with the data usage. The generalized, comparable score will help to prioritize your findings. Some of the results might be of greater value or impact for your company. Some might be expected and are just tracked for reporting issues. Thus, we encourage establishing a Data Quality Council consisting of all stakeholders, which meets regularly to align on priorities of DQ findings. This is especially important if the mitigation of different DQ problems will be executed by the same analytical or developer resources.
“So what do we do about this?”
The mitigation of data quality issues ideally includes a root cause analysis. This activity is infinitely easier if the organization has a clear view on its data lineage: the original source of the information, processing steps like transformation and transfer operations must be transparent for an analysis to be efficient. Ideally, this information is available in an organization-wide data catalog, along with further information like data ownership and business definitions of attributes. Once the root cause is identified, business analysts and developers would coordinate a plan to fix the underlying issue, or, if that is not possible, come up with a way to mitigate the impact.
The actual implementation of a mitigation strategy ideally can be executed in an automized way: rule-based, with heuristics or even with machine learning models. But you will also have cases that need to be fixed manually by your data source owners using the regular IT service management process: Tickets need to be written, issues to be fixed and tested along the way.
Lifelong learning, also in Data Quality terms
From the analysis of prior findings, DQ officers can deduce new data quality requirements and checks or to identify old or unnecessary checks. Additionally, statistical analyses or applied machine learning models (e.g. for monitoring) can lead to gain of knowledge and useful new DQ checks by identifying unusual value combinations or statistical outliers. Regarding the interpretation of rules, automatic interpretation schemas can be adjusted if threshold values are determined to be too low or too high. This process step leads to gradual improvement of the overall quality – of both the process precision and the data.
The essence of it all
The overall goal of a data quality framework, in our perspective, is to get rid of quality issues in a sustainable way. Many market tools and proposals focus on an aggregated reporting of data quality KPIs and offer data cleansing mechanisms to correct data at a later stage in the process. Our approach focuses on improving the ‘quality at source’ instead, making data quality efforts sustainable and keeping the overall DQ system manageable. Also, the scope of the framework in terms of the number of checks and the data scope can be flexibly adjusted, if checks or scope need to be added or removed. To make the solution work in the long run, it is vitally important to consider both rule-based checks and their rigid upkeep, as well as more automatable, holistic approaches enabled by advanced analytics and machine learning.
How to nail technical details and boost your Data Quality Management?
Designing processes is just one side of the whole story.
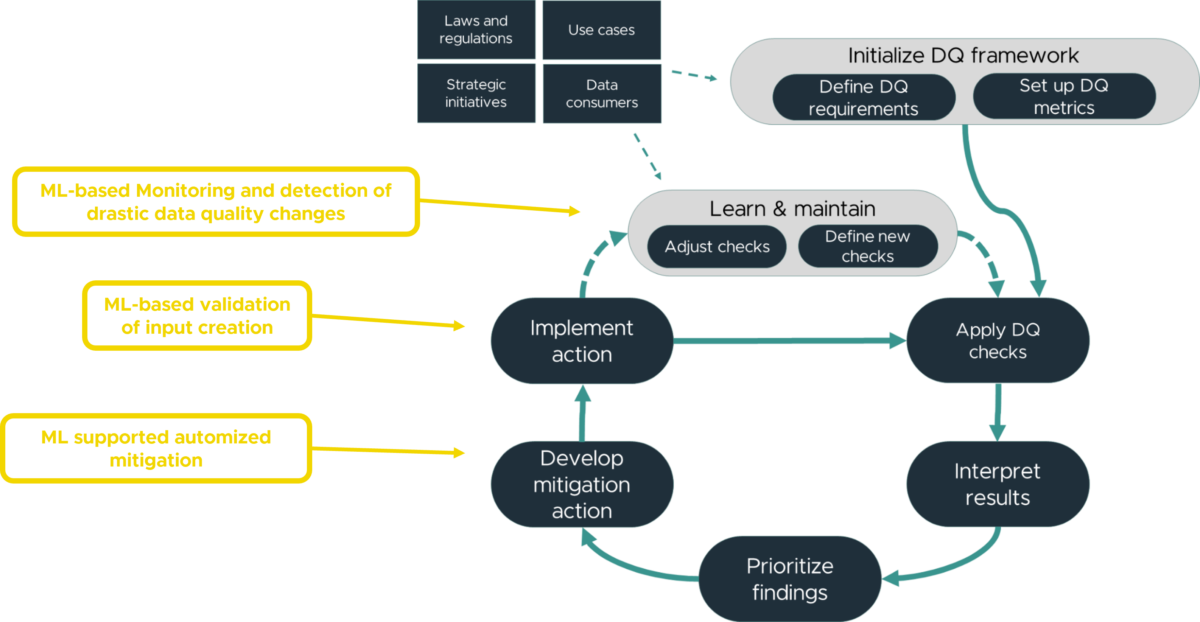
Would you like to learn more about the technical design of Data Quality Frameworks, practial implementation details, and how to boost Data Quality Management with machine learning capabilities?
Vera Meinert from Positive Thinking Company, a partner brand from our ecosystem, wrote an article on how you can enhance your Data Quality Framework by:
- Machine Learning based Monitoring and detection of drastic data changes
- Machine Learning based validation of input creation
- Machine Learning supported automized mitigation
Take a look at Vera’s article on how Machine Learning enhances Data Quality Management.

Data Strategy & Governance Consultant
Brought to you by Lennard
Lennard Nobbe has a vast experience in data architecture and data governance in the banking industry, and, having experienced organizational mindsets change from a front-row seat, is convinced that organizations‘ ability to manage and utilize data, or lack thereof, will determine their role in the very near future.